Atomのlinter-spellで日本語が指摘されないようにするlinter-spell-cjkを書いた
最近AtomでGoを書いたりなどして、なかなかいいねと思ったので、日本語文書もこのままAtomでいくぞ〜と思ったら、spell checkに使っているlinter-spellが大暴れ。いたるところに下線がひかれ、なにがなんだかわっかんない。
こんな感じよ
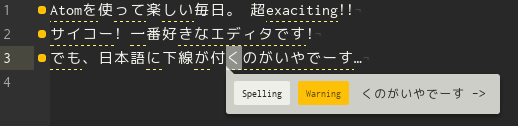
しかも、何が悪いんだと表示されるtipsを見ても、たとえば「くのがいやでーす」は、英語の辞書にないからだめだよ?ということしか言ってこない。こんなにあちこち線をひかれてもなにもわからん。ぐぐってみると、"spell check pluginを無効にしようね"とかあって、嘘でしょそんな〜っ、英語の部分はきっちりspell checkされたいでしょと思うわけです。
ってことで、日本語とかが指摘されないようにするプラグインlinter-spell-cjkを作った。こんな感じにすっきりしてくれる。これなら"exaciting"ってtypoってたことがわかってしまう。

とりあえず公開した
画像を見るとわかるように、現状では「Atomを」みたいに英語と日本語をまたがって引かれていた線は消えていない。このへんは将来の課題ということで・・・
しかし、linter-spell側にいろいろ手を入れずにその変更をするのは困難だと思われる。linter-spellは、まずprimary dictionary engineに全文を渡す。primaryは、tokenizeして、spell checkして、スペルミス候補の単語リストを返す。返ってきた単語は、追加辞書がさらにチェックして、「スペルミスではない」とか「追加修正候補はこれだ」とか言ってくる。linter-spell-cjkは、この追加辞書として機能して、渡された単語が全て日本語文字で構成されていたら、「これは辞書にあるOKな単語だ」と返している。
日英交ざった単語が降ってきた場合、1) 英語の部分をとりだす 2) 英語の部分をprimary辞書でcheck 3) 間違ってたら、候補を返す, ということをしたい。(1)はregexでOK。(2)はprimaryの辞書は現状わからんが、English hunspellを呼ぶよ、みたいな感じでよさそう。(3)が問題で、いまのlinter-spellだとrangeを変えられないので「primaryは、ここが単語って言ってきたけど、本当はもっと狭いこの部分が単語で、これが修正候補だよ」ということができない。
ということで、linter-spell側でprimary辞書くれて、rangeを狭めることができるようになるといいなあ。
あと、このpackageでは regexp のunicode propertyを使ってて、単純にatomのbabelだと自動でそのへんをtranspileしてくれん(babel pluginが認識されてない?)ので、手でtranspileしてるんだけど、これってなんとかなんないんでしょうか。教えてください、atom packageにくわしい人